
¹University of California, Merced
²The University of Queensland
EMNLP 2025
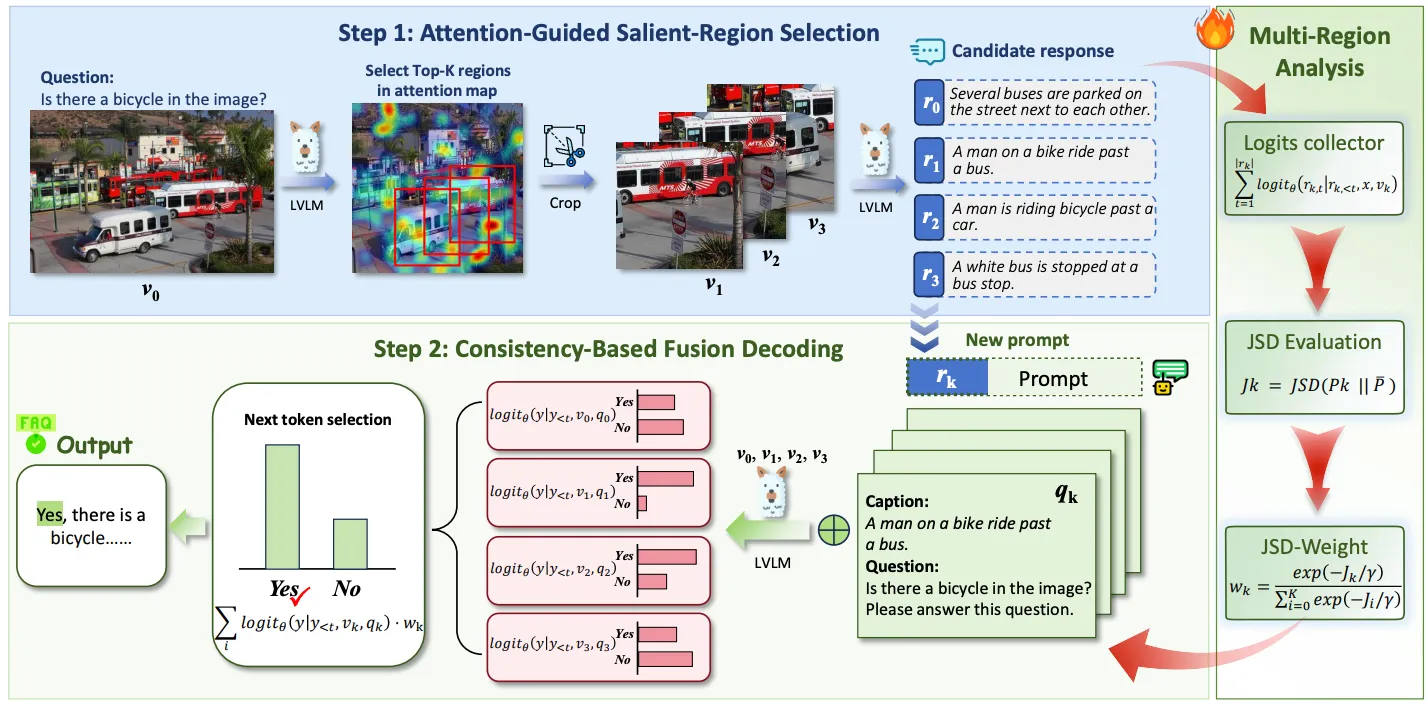
Large Vision-Language Models (LVLMs) have shown strong performance across multimodal tasks. However, they often produce hallucinations — text that is inconsistent with visual input, due to the limited ability to verify information in different regions of the image. To address this, we propose Multi-Region Fusion Decoding (MRFD), a training-free decoding method that improves factual grounding by modeling inter-region consistency. MRFD identifies salient regions using cross-attention, generates initial responses for each, and computes reliability weights based on Jensen-Shannon Divergence (JSD) among the responses. These weights guide a consistency-aware fusion of per-region predictions, using region-aware prompts inspired by Chain-of-Thought reasoning. Experiments across multiple LVLMs and benchmarks show that MRFD significantly reduces hallucinations and improves response factuality without requiring model updates.
@article{ge2025mrfd,
title={Mrfd: Multi-region fusion decoding with self-consistency for mitigating hallucinations in lvlms},
author={Ge, Haonan and Wang, Yiwei and Yang, Ming-Hsuan and Cai, Yujun},
journal={arXiv preprint arXiv:2508.10264},
year={2025}
}